글
네이버 일본검색 엔진, 정보 모으기는 성공할까
NHN(네이버)가 최근 일본의 검색 시장 공략을 위한 새 검색 엔진의 전용 크롤러(검색로봇, User Agent)를 국내 웹사이트를 대상으로 본격 가동하기 시작했다.
이에 앞서 네이버는 지난 3월 말부터 일본내 검색엔진 사업을 준비하기 위해 일본어 웹페이지에 대한 검색 색인 정보가 수집 활동을 시작했었다. 국내 검색 엔진의 해외 시장 본격 진출을 알리는 네이버의 일본어 검색서비스는 내년에 시작될 예정이다.
일본어로 검색 서비스를 준비중인, 네이버의 일본 검색엔진이 왜 한국어 웹 페이지를 대상으로 색인 정보를 수집해 가는 지는 아직 미지수이다.
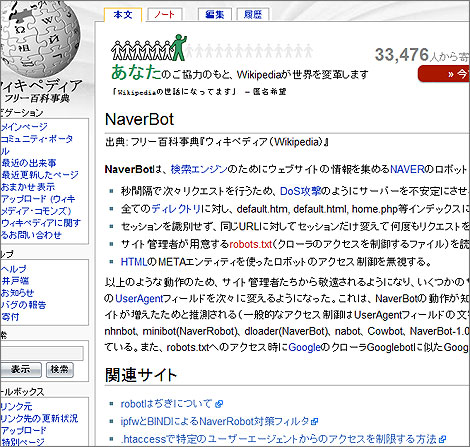
- ▲ 네이버봇의 문제점을 지적하고 있는 위키피디아 일본어판. 특정 검색엔진 로봇의 문제점이 온라인 백과사전에 소개된 것은 매우 이례적이다. / 서명덕 기자
조선일보가 5일 확인한 자료에 따르면 내년 초 일본 진출을 계획하고 있는 네이버는 현재 알파 단계의 검색엔진을 개발 완료하고 테스트를 진행하고 있다.
실제로 지난달부터는 '예티(Yeti/0.01 nhn/1noon, yetibot@naver.com, check robots.txt daily and follow it)'라는 이름의 웹사이트 검색로봇이 일부 국내 한글 홈페이지들을 매일 수십~수백차례씩 방문하고 있는 것으로 파악됐다. 또한 해당 크롤러의 IP 주소 역시 61.247.219.41 ~ 50 등으로 다양해 상당한 수의 검색 로봇이 국내 웹사이트를 동시에 훑고 있는 것으로 파악된다.
특히 '첫눈(1noon)'이라는 명칭을 로봇 제작자 nhn과 병기한 점, 그리고 '설인(雪人)'을 뜻하는 'Yeti'를 로봇 명으로 사용했다는 점에서 첫눈(http://www.1noon.com)의 스노우랭크 검색 기술이 기반이 됐음을 간접 시사하고 있다.
네이버는 그 동안 웹 검색 서비스를 위해 '네이버봇'(Mozilla/4.0 compatible; NaverBot/1.0; http://help.naver.com/delete_main.asp)이라는 이름의 크롤러를 간헐적으로 운영해 왔으나, 국내에선 활발하게 활동하지 않았다. 이는 네이버의 검색 서비스가 웹 검색에 촛점이 맞춰진 것이 아니라, 네이버 내부의 통합 검색에 집중되었기 때문이다.
◆日서는 지난 3월부터 새로운 검색엔진 '예티' 가동된 듯…'네이버봇'의 실패를 극복할까?
네이버의 새로운 검색 로봇 예티는 어도 지난 3월 말부터 활발한 활동을 하며 일본 주요 웹사이트를 수집한 것으로 보인다. 이에 대해 일부 일본 네티즌들은 "한국 네이버에서 온 검색 로봇"이라며 경계하고 있다.
조선일보 취재 결과 네이버 재팬은 일본 웹사이트를 검색하기 위해 지난 3월 말까지 운영한 크롤러 '네이버 봇(Naverbot)'이 웹사이트 안정성을 훼손할 정도로 빈번하게 웹사이트에 접속했다는 비판을 받았다. 특히 서버가 튼튼하지 않은 일본내 영세 웹 사이트 관리자들로부터 비판을 받았던 것으로 확인됐다.
실제로 세계적으로 유명한 백과사전 위키피디아 일본어판에서는 '네이버봇'(http://ja.wikipedia.org/wiki/NaverBot)에 대해 비판적인 설명을 하고 있다. 위키피이다 일본어판은 "과거 네이버봇은 크롤러로서 알고리즘이 나빠 문제가 됐다"며 "거의 초 단위로 리퀘스트를 실시하면서, DoS 공격과 유사한 정도에 달해 서버를 불안정하게 할 우려가 있다"고 비판하고 있다.
이 자료에서는 "네이버봇은 일본어 웹사이트를 수집할 때 인덱스에 사용될 것 같은 웹페이지들을 유무를 확인하지 않고 무차별 확인한다"며 "세션을 식별하지 않을 뿐만 아니라, 같은 URL에 대해서 세션만 바꾼 채 잇달아 리퀘스트를 실시하고 있고, (검색엔진이 지켜야 하는 공통 국제규약인) robots.txt도 무시한다"고 지적했다.
또 이 사전에서는 "NABOT/5., nhnbot, minibot(NaverRobot), dloader(NaverBot), nabot, Cowbot, NaverBot-1.0+ 등 다양한 방식으로 이름을 바꿔 웹사이트에 접근했다"며 "네이버봇을 거부하는 일본 웹사이트가 증가했다"고 소개했다.
이와 관련 일본의 한 검색엔진 전문 블로그(http://www.seiren-udoku.com) 운영자는 지난 4월 초 올린 글에서 "네이버봇은 자주 크롤러(HTTP_USER_AGENT) 명칭을 바꾸는 것으로 유명하다"며 "지난 3월 26일을 마지막으로 네이버봇 접근이 사라졌으며, 3월 29일부터는 '예티'라는 새 이름으로 접근하고, IP 주소도 바뀌었다"고 확인하고 있다.
이 뿐만 아니라 일본 주요 포털사이트나 블로거들 역시 "네이버봇을 주의해야 한다"고 말하고 있다. 야후 재팬은 물론이고 구글 재팬에서도 '네이버봇 거부 금지(일본어로 NaverBot 拒否/禁止)' 등의 단어로 검색하면 수십~수백건의 글이 쏟아진다.
이러한 분위기가 수그러들지 않으면서 네이버가 새로 내 놓은 검색로봇 '예티'까지 네이버봇의 악명을 물려 받고 있는 형국이다. 로봇이 본격 가동되면서 일본 웹사이트 관리자들은 "또 네이버가 이름을 바꿨는가"라는 의견을 잇달아 내 놓고 있다. 예티의 크롤러 서버 IP를 직접 파악해 원천적으로 막는 일본 네티즌들도 다수 있을 정도다. 검색엔진 접근이 잇달아 차단되면 색인이 불가능하기 때문에 당연히 검색 품질이 떨어질 수 밖에 없다.
일본 네티즌들은 야후, 구글, 바이두의 검색로봇 접근 횟수와 네이버 예티 로봇의 접근 횟수를 비교한 자료를 제시한 뒤, 예티가 너무 빈번하게 웹 사이트의 색인 정보를 긁어가고 있다고 비판하고 있다.
이에 대해 네이버 관계자는 "과거 일본어 검색에 이용됐던 네이버봇과 달리, 새로운 로봇은 통상적인 수준의 작업을 하고 있다"며 "야후나 구글도 크롤링 빈도가 만만치 않다"고 말했다. 네이버측은 일본 웹 사이트의 관리자로부터 원성을 듣지 않으면서, 동시에 일정 검색 서비스 품질을 유지하기 위한 합리적인 수준의 웹 크롤링을 하기 위해 고민중인 상태이다.
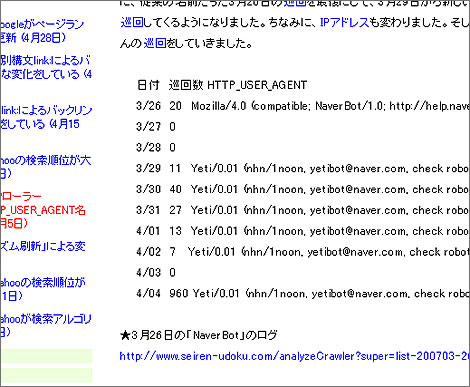
- ▲ 지난 4월 네이버 재팬의 '예티' 검색로봇의 등장을 알리고 있는 일본 블로거 / 서명덕 기자
◆중국 최대 검색엔진 '바이두'도 유사 논란에 공식사과
사실 일본에 진출 검색엔진이 검색로봇 때문에 일본 네티즌들의 반발을 산 것은 비단 네이버 뿐만이 아니다.
중화권 최대 검색엔진 바이두(百度, http://baidu.com)가 지난해 말 ‘일본 진출’을 선언했지만, 올해 초 일부 일본 개발자들을 중심으로 ‘反바이두’ 움직임이 일었다.
사태의 발단은 바이두가 지난해 말 첫 해외 진출로 “일본에서 일본어 서비스를 시작하겠다”고 밝히면서다. 바이두는 12월부터 본격적으로 일본어 검색로봇 ‘바이두 스파이더(Baiduspider)’를 가동하며 일본 웹사이트 정보를 무차별 수집(인덱싱)하기 시작했다.
문제는 바이두 검색로봇이 많게는 1초에 수차례 웹서버에 접근하는 등 지나치게 웹사이트를 훑는 경우가 많아 사이트 안정성을 위협할 지경에 이르렀던 것이다. 구글이나 야후 재팬 등 주요 검색사이트에서 ‘Baiduspider’ 등의 키워드로 검색하면 “바이두 검색로봇 접근을 막겠다” “바이두 검색로봇은 웹서비스 기본 예의가 없다”는 등 비난하는 의견이 쏟아졌다.
당시 사태가 악화되자 바이두 일본어 서비스 담당자는 지난 2월 17일 아직 개설하지도 않은 바이두 일본어 홈페이지(http://www.baidu.jp)에 ‘진심으로 사과한다’는 임시 공지사항을 내걸고 사태 진화에 나섰지만 부정적인 시선을 무마하기에는 역부족이었다.
‘일본 웹사이트 관리자에게 보내는 메시지’라는 이 공지에서 바이두는 “해외 첫 진출인 일본 시장에는 지난해 12월부터 본격적으로 진출했다”며 “일본어 검색서비스를 하기 위해 일본어 사이트 정보를 수집하는 검색로봇 리서치를 실시하고 있다”고 말했다. 이러한 과정에서 일부 웹사이트에 과도한 접근(액세스)이 발생, 관리자들에게 막대한 영향을 끼쳤다는 설명이다.
바이두 측은 “바이두 담당자로서 바이두 검색로봇이 사이트에 피해를 끼친 점을 정말 미안하게 생각한다”며 “향후 이 문제에 대해 회사 전반에서 진지하게 받아들이고, 일본 인터넷업계의 규칙에 따라 두번 다시 이런 일이 없도록 노력하겠다”고 덧붙였다.
현재 일본 검색 시장은 소프트뱅크와 손잡은 야후재팬이 부동의 1위를 달리고 있으며, 구글 재팬이 2위로 그 뒤를 추격하고 있다.

- ▲ 바이두 재팬이 지난 2월 웹사이트에 게재한 공식 사과문. / 서명덕 기자
◆검색로봇(크롤러) = 검색엔진이 검색 데이터베이스의 내용을 색인 및 보충하기 위해, 대상 웹페이지를 자동으로 검색하여 가져오는 컴퓨터 소프트웨어다. 검색 서비스를 제공하기 위해서는 반드시 검색로봇이 돌아다니면서,정보를 수집해와야 한다. 보통 스파이더(spider), 봇(bot), 지능 에이전트 등으로도 불린다. 검색로봇은 새로운 웹페이지를 찾아 종합하고, 찾은 결과를 이용해 또 새로운 정보를 찾아 색인을 추가하는 작업을 사람의 개입 없이 반복 수행한다.
검색로봇에 의해 검색되지 않기를 원하는 웹 자료는 저장할 때 HTML파일 내에 검색을 거부하는 것을 명시한 메타태그(Meta Tag)를 써 넣거나 웹 서버의 공개 디렉토리 최상위 영역에 로봇 검색 영역을 규정하는 robots.txt를 넣으면 된다.
'렛츠웹 + 게임 > IT News' 카테고리의 다른 글
| '미운오리' P2P, 회선비 절감 대안으로 급부상 (0) | 2009.01.06 |
|---|---|
| 쇼핑몰, 해외 구매대행 서비스 `속속 (0) | 2009.01.06 |
| 다음, 오픈 플랫폼에 기반한 지도 API 공개 (0) | 2009.01.05 |
| 5가지 기술 트렌드가 5년후 사회 바꾼다 (0) | 2009.01.05 |
| "블로그는 기성 뉴스에 없던 '대화'를 복원한 것" (0) | 2009.01.05 |


